- hsfzbzjr's blog
从注意力机制到注意力涣散——《Attention is all you need》阅读笔记
-
 hsfzbzjr
LV 7
@
2024-7-15 17:52:15
hsfzbzjr
LV 7
@
2024-7-15 17:52:15
Day1
如果公式炸了记得私信我
为与正文做区别,标题都上了颜色
颜色丑的话,记得私信我换颜色
[toc]
$\displaystyle \text{\color{66ccff}{《Attention is all you need》}}$
- RNN 中需要大量的串行计算,无法利用硬件(GPU)可以进行大规模并行计算的特点
- RNN 无法很好的处理长序列间的关联(反向传播过程中发生梯度爆炸或梯度消失)
- CNN 虽然减少了串行计算的数量,但是 CNN 一次只能提取到局部的信息,无法注意到长距离的关联,为了补足这一缺陷,需要堆叠多层卷积,最终导致大量的信息丢失以及操作数量成对数或线性级别的增长
- Transformer 是第一个完全依赖 Self-attention 来计算输入和输出的表示的转换模型,而且可以使计算任两个词之间的相似度做到常数级别
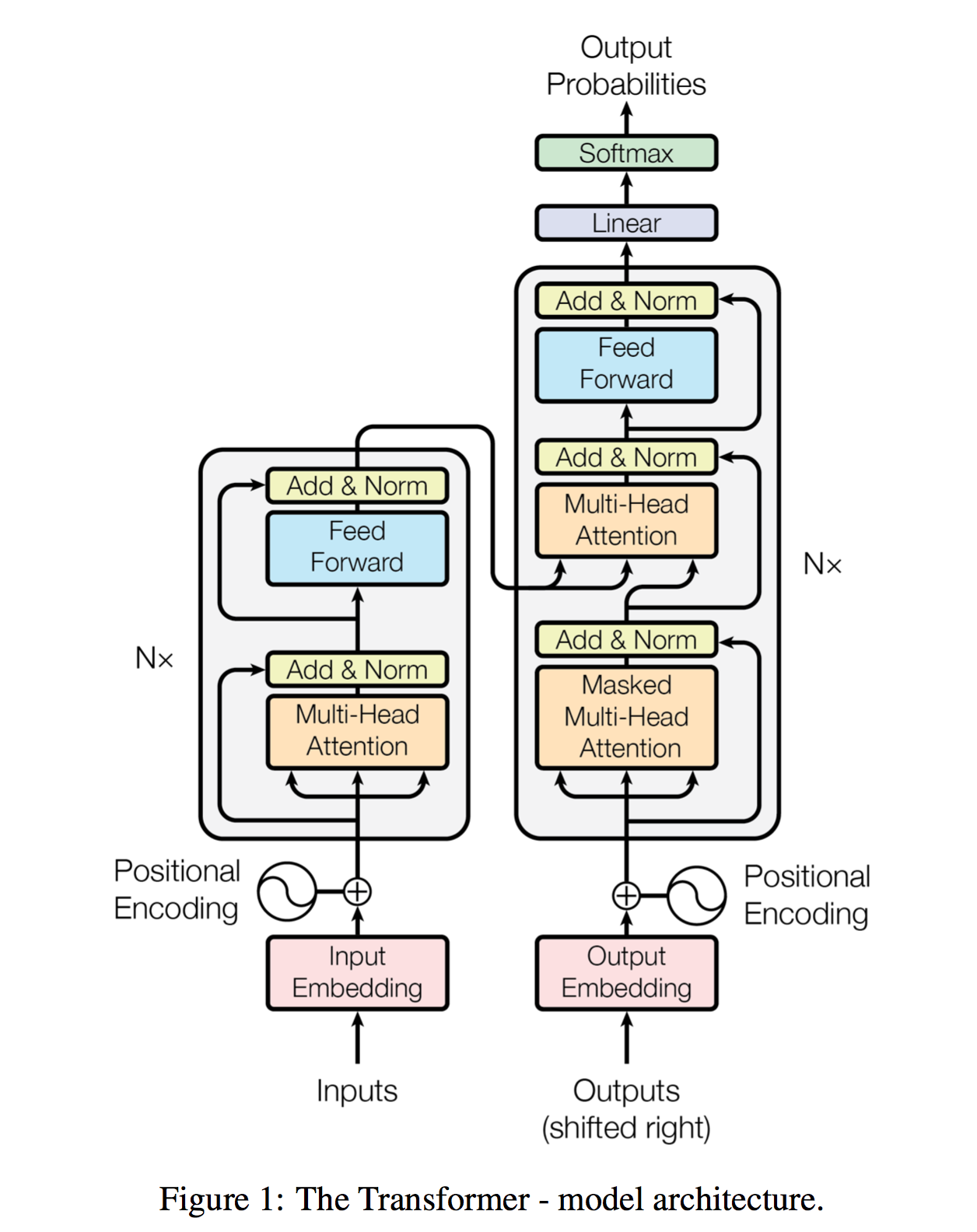
模型分为两个部分:Encoder(左侧)和 Decoder(右侧)
Encoder 将一个符号表示的输入序列 映射为一个连续表示的序列
通过 ,Decoder 将逐字(元素)地生成一个符号表示的序列
Encoder 和 Decoder 主要由两种模块组成:多头注意力模块和前馈网络模块
The animal didn't across the street because it was too tired.
The animal didn't across the street because it was too wide.
通过一个单词的上下文来推断该单词的含义
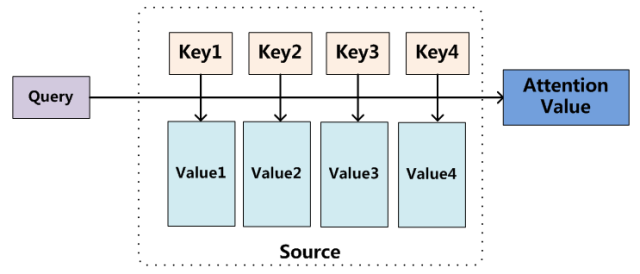
将 query 与一组 key-value 对映射到一个输出,将每一个 value 加权后求和,权重由 query 与对应的 key 的相似度决定
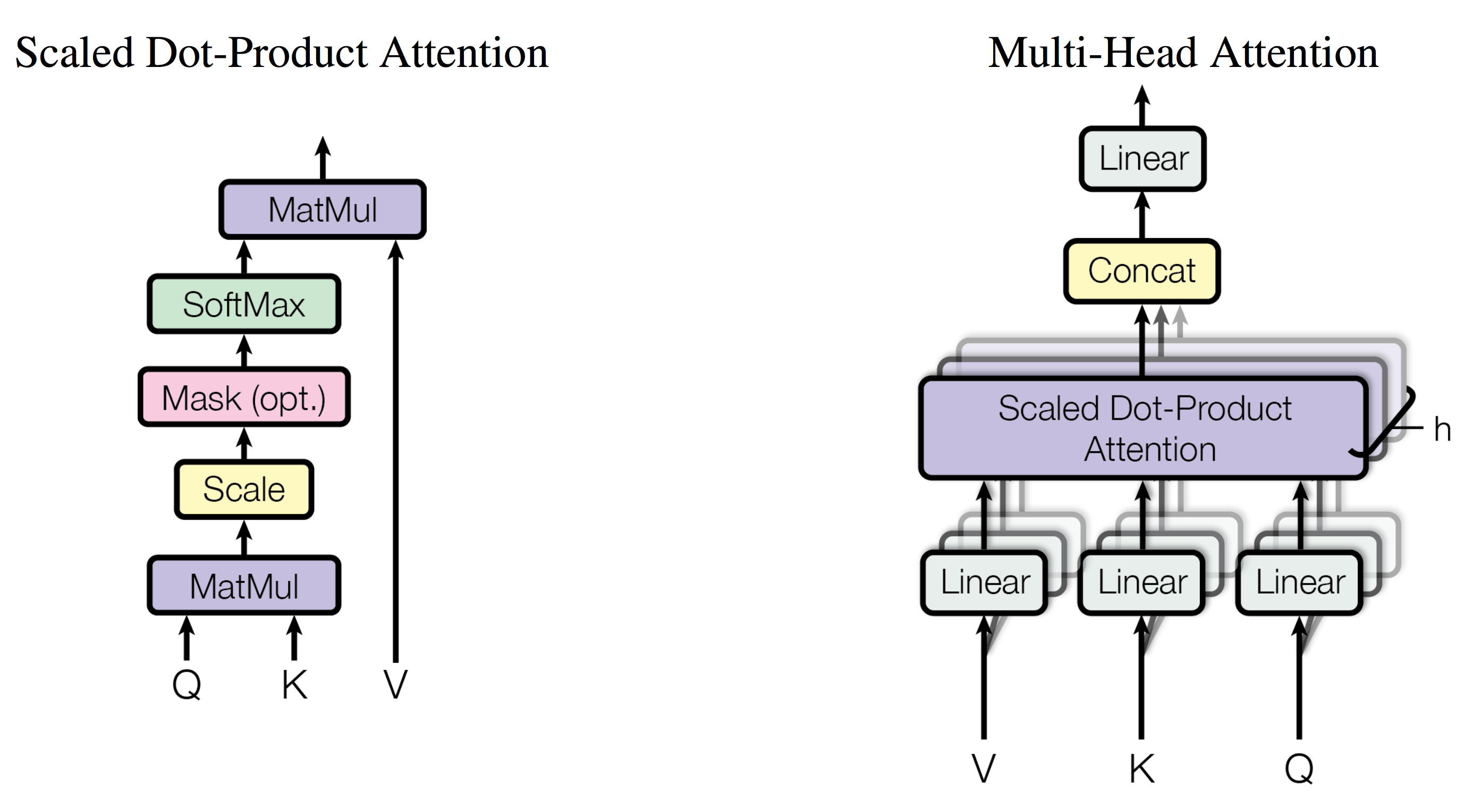
$$Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V$$将一组 query 打包成矩阵 Q ,将 key 和 value 分别打包成矩阵 K 和 V ,于是我们可以通过矩阵乘法同时计算多组 query 的注意力函数
$\scriptstyle\color{66ccff}{QK^T}\text {\color{66ccff} {的含义}}$
考虑一个简化情况,我们的 Q 里面只有一个 query ,K 中只有一个 key
query 和 key 都是一个向量
那么在该情况下 为一个 的方阵,其中唯一一个元素的数值等于 query 和 key 的内积,也就是这两个向量对应的 token 的相似度
于是,当我们的 Q 和 K 中包含若干组 query 和 key 时, 中实际上包含了若干对 token 之间的相似度
通过给 乘上 来使 的结果变得相对平均(从网上材料中摘得,并不理解实际原因)
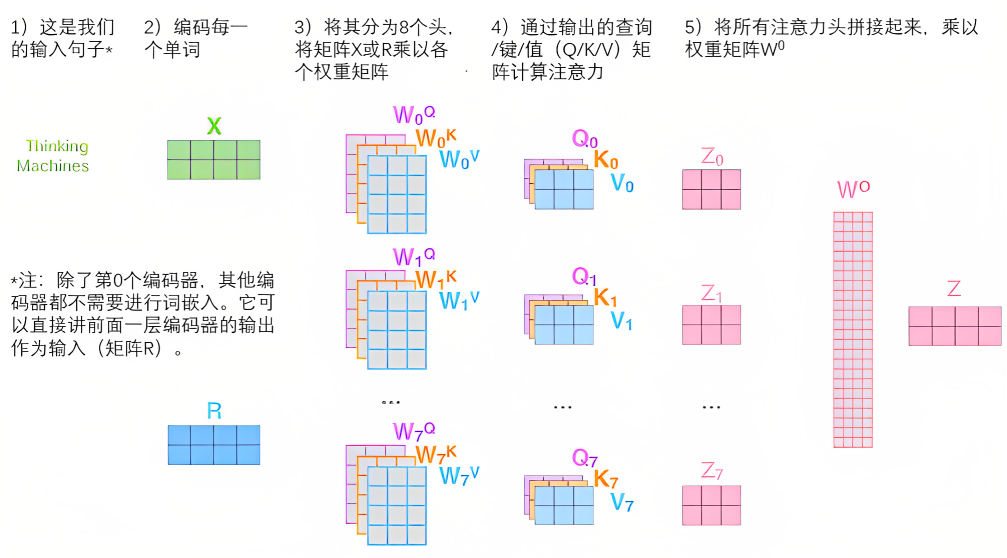
$\text {\color{66ccff} {Multi-Head Attention(多头注意力机制)}}$
$$MultiHead(Q,K,V)=Concat(head_1,head_2,\dots,head_h)W^O \\ \text{where} \, head_i=Attention(QW_i^Q,KW_i^K,VW_i^V)$$Attention 可以视作将 query 和 key 映射到同一个高维空间去计算相似度
而 Multi-Head Attention 则是将 query 和 key 映射到高维空间 的不同子空间中去计算相似度
而且该过程可以并行计算(同时做多个 Attention 过程)
$\scriptstyle\text {\color{66ccff} {Self-Attention\&Cross Attention}}$
Encoder 和 Decoder 最底下的一个 Multi-Head Attention 模块都是 Self-Attention 的,即考虑同一个序列内元素间的关联度
而 Decoder 中的第二个 Multi-Head Attention 模块是 Cross-Attention 的
Transformer 模型最初适用于做语言翻译,如英语到德语,在这个 Cross-Attention Layer 中,考虑的是两个序列内元素间的关联度,以便在两种语言的单词的 token 之间建立联系
由于每个批次的输入序列长度不一定相同,所以我们需要对输入序列进行对齐
具体来说,就是在较短序列后面填充 0
另外,按照网上资料的说法,由于硬件限制,一次 Attention 能注意到的序列的长度是有限的,所以我们需要截掉太长的部分,具体处理方法是在这些位置的值上加上 ,于是这些位置在 之后就会接近
与 RNN 不同,Transformer 是一次性读入全部文本,为了使得 Decoder 不会看见未来的信息,需要将某一些 token 之间的相似度信息遮盖掉
具体处理方式是在计算 后,该矩阵的右上半部分是涉及到未来的信息,把这一部分的值全部置为 ,在后续的 过程中,这一部分的值就会接近 ,从而达到了遮盖的效果
$\text {\color{66ccff} {最后的 Linear 层和 softmax 层的作用}}$
Decoder 最后会输出一个浮点型的向量,我们需要将其还原为一个词
Linear 层将这个向量映射一个名为 Logits 的向量中,再对 Logits 向量做 softmax 操作。
现在 Logits 向量的每个位置的数值代表的当前时间步的输出为单词表中对应位置的单词的概率。(说起来好绕啊)
由于 Transformer 不包含任何的循环或卷积,所以为了使模型能够利用序列的位置信息,需要在输入矩阵中嵌入位置编码
$$PE_{(pos,2i)}=\sin(pos/10000^{2i/d_{model}}) \\ PE_{(pos,2i+1)}=\cos(pos/10000^{2i/d_{model}})$$